


tesseract识别率太低
软件: tessera




Tesseract OCR 识别率低是一个常见问题,通常由多种因素导致。以下是综合多个搜索结果后总结的优化方案,按优先级排序:
1. 图像预处理
图像质量是影响识别率的核心因素。以下预处理步骤可显著提升效果:
灰度化与二值化:将彩色图像转为灰度图,再通过阈值处理(如OpenCV的THRESH_BINARY)增强文字对比度。示例代码:
import cv
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY)
去噪与增强:使用高斯模糊或中值滤波去除噪点,通过ImageEnhance调整对比度或亮度。
旋转矫正与边界处理:歪斜的文本需通过cv2.getRotationMatrix2D矫正,扫描文档可添加白色边框避免边缘干扰。
2. Tesseract参数优化
语言与PSM模式:
确保安装正确的语言包(如中文简体chi_sim),并通过-l参数指定。
根据文本布局选择页面分割模式(PSM),例如:
--psm 6:单块文本(如身份证)。
--psm 11:稀疏文本(如收据)。
OEM引擎选择:--oem 3(默认)结合LSTM和传统算法,适合多数场景。
3. 训练数据与模型
使用优化版语言包:如tessdata_fast或tessdata_best,针对特定语言优化。
自定义训练:若识别特定字体(如身份证专用字体),可通过jTessBoxEditor工具微调模型。
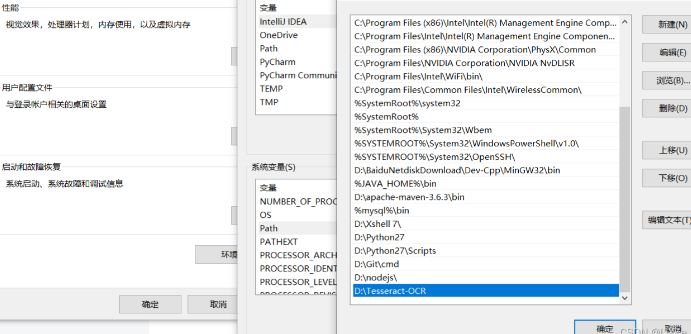
4. 环境与版本调整
版本兼容性:某些场景下,Tesseract 4.x比5.x更稳定(如中文识别)。
环境变量配置:确保TESSDATA_PREFIX指向正确的tessdata目录,避免语言包加载失败。
5. 替代方案
若上述方法无效,可尝试:
深度学习OCR工具:如EasyOCR、PaddleOCR,对复杂场景(手写体、低对比度)表现更好。
商业OCR服务:腾讯云OCR等提供高精度API,适合企业需求。
快速排查清单
检查图像是否清晰(DPI建议≥300)。
确认语言包存在且路径正确。
尝试不同PSM和OEM组合。
对图像进行二值化和去噪。
通过逐步排查和优化,Tesseract的识别率通常可大幅提升。若需进一步调试,建议提供具体图片和代码片段以便针对性分析。
1. 图像预处理
图像质量是影响识别率的核心因素。以下预处理步骤可显著提升效果:
灰度化与二值化:将彩色图像转为灰度图,再通过阈值处理(如OpenCV的THRESH_BINARY)增强文字对比度。示例代码:
import cv
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY)
去噪与增强:使用高斯模糊或中值滤波去除噪点,通过ImageEnhance调整对比度或亮度。
旋转矫正与边界处理:歪斜的文本需通过cv2.getRotationMatrix2D矫正,扫描文档可添加白色边框避免边缘干扰。
2. Tesseract参数优化
语言与PSM模式:
确保安装正确的语言包(如中文简体chi_sim),并通过-l参数指定。
根据文本布局选择页面分割模式(PSM),例如:
--psm 6:单块文本(如身份证)。
--psm 11:稀疏文本(如收据)。
OEM引擎选择:--oem 3(默认)结合LSTM和传统算法,适合多数场景。
3. 训练数据与模型
使用优化版语言包:如tessdata_fast或tessdata_best,针对特定语言优化。
自定义训练:若识别特定字体(如身份证专用字体),可通过jTessBoxEditor工具微调模型。
4. 环境与版本调整
版本兼容性:某些场景下,Tesseract 4.x比5.x更稳定(如中文识别)。
环境变量配置:确保TESSDATA_PREFIX指向正确的tessdata目录,避免语言包加载失败。
5. 替代方案
若上述方法无效,可尝试:
深度学习OCR工具:如EasyOCR、PaddleOCR,对复杂场景(手写体、低对比度)表现更好。
商业OCR服务:腾讯云OCR等提供高精度API,适合企业需求。
快速排查清单
检查图像是否清晰(DPI建议≥300)。
确认语言包存在且路径正确。
尝试不同PSM和OEM组合。
对图像进行二值化和去噪。
通过逐步排查和优化,Tesseract的识别率通常可大幅提升。若需进一步调试,建议提供具体图片和代码片段以便针对性分析。
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks ,Hyperworks, Protel,CAXA,OpenWorks LandMark,MATLAB,Enovia,Winchill,TeamCenter,MathCAD,Ansys, Abaqus,ls-dyna, Fluent, MSC,Bentley,License,UG,ug,catia,Dassault Systèmes,AutoDesk,Altair,autocad,PTC,SolidWorks,Ansys,Siemens PLM Software,Paradigm,Mathworks,Borland,AVEVA,ESRI,hP,Solibri,Progman,Leica,Cadence,IBM,SIMULIA,Citrix,Sybase,Schlumberger,MSC Products...
相关推荐





